1. 单链表的概念
1.1. 什么是链表
链表是一种线性表数据结构,它不需要连续的存储空间,各个元素可以分散存储在内存中,通过"指针"将零散的内存块串联起来。
关键词:
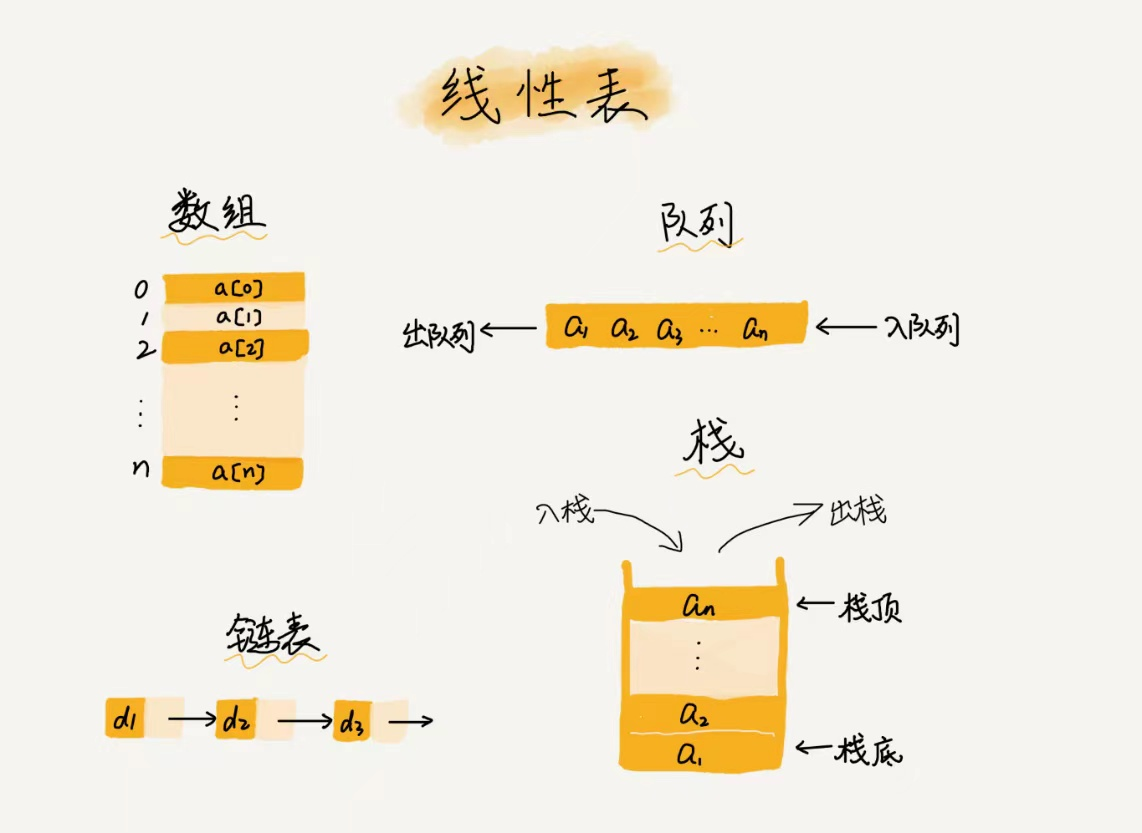
线性表
线性表:即数据排成像一条线一样的结构。每个线性表上的数据最多只有前后两个方向。包括数组、队列、栈等也是线性表结构。
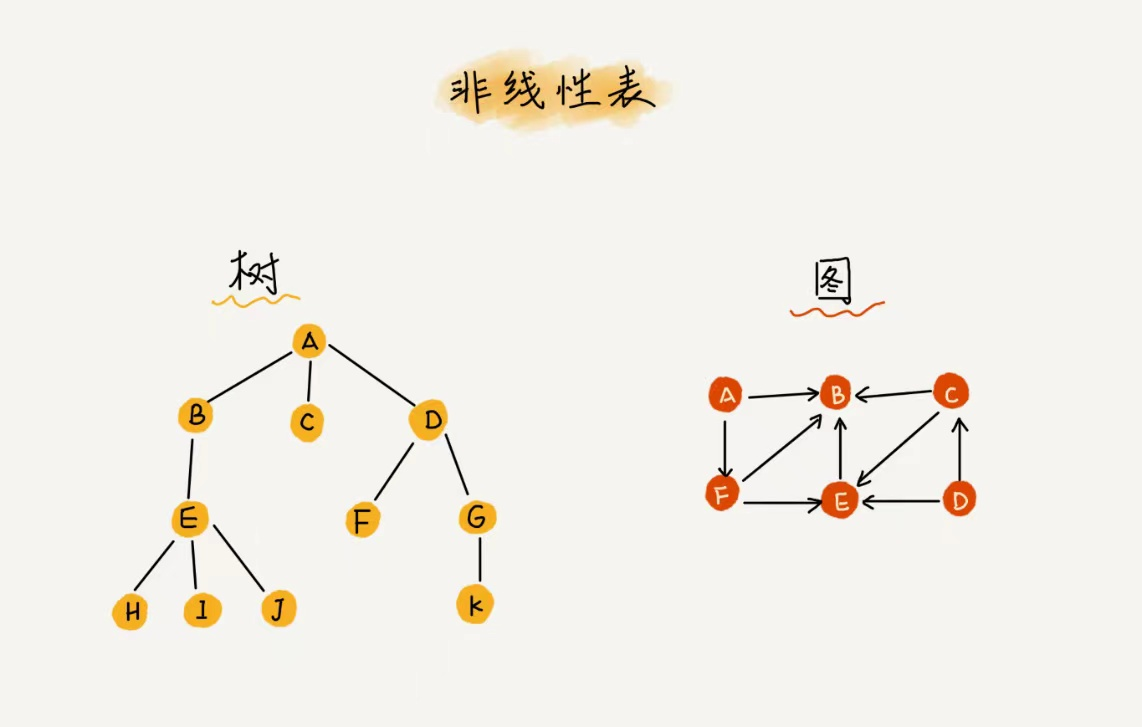
与之对立的,非线性表,数据之间不是简单的前后关系,如二叉树、堆、图等。
不需要连续的存储空间
链表数据不需要集中存放,每个元素所存储的内存块称之为"结点",每个结点存储数据之外,还需记录下一个结点的地址,即后继指针 next 。
另外,链表中每个结点只能有一个后继,但是一个结点可以被多个结点指向,如下:
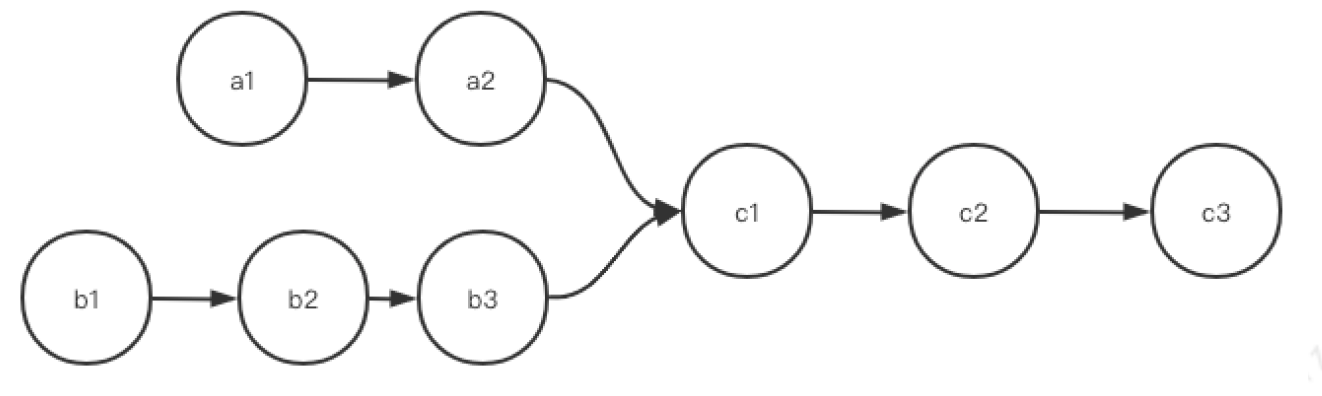
上图数据结构是满足链表要求的;
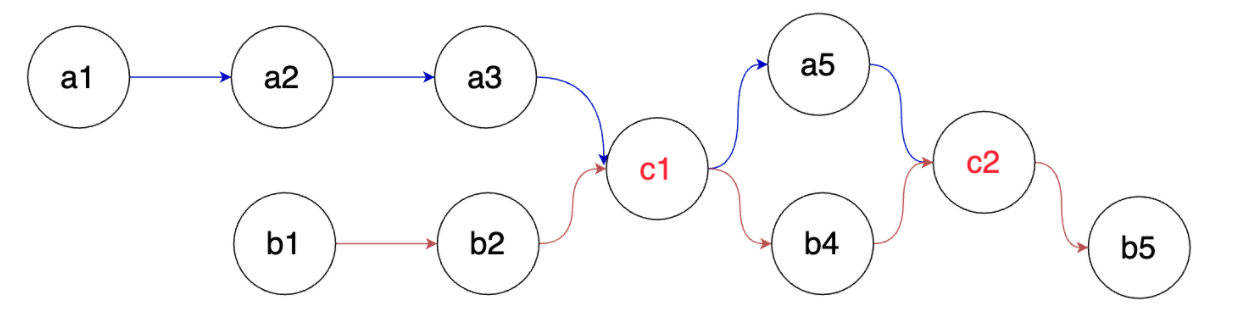
此图中的数据结构是不满足链表要求的;
1.2. 链表的相关概念
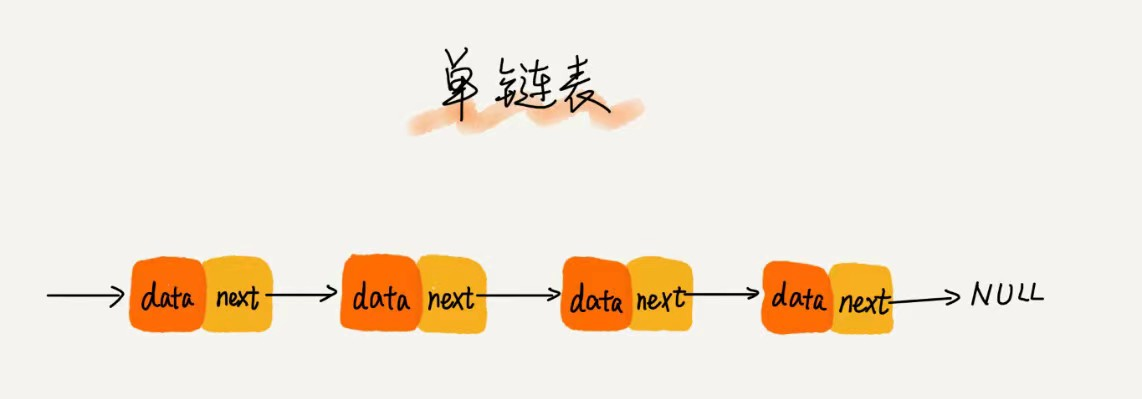
在链表中,存储数据和下一个元素地址的内存块称之为结点;在单链表中,有两个特殊的结点,第一个结点叫做头结点,最后一个结点为尾结点,其中尾结点的指针不是指向下一个结点,而是指向一个空地址 NULL。
2. 创建链表
在Java中规范的链表应该这么定义:
public class ListNode {
private int data;
private ListNode next;
public ListNode(int data) {
this.data = data;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public ListNode getNext() {
return next;
}
public void setNext(ListNode next) {
this.next = next;
}
}实际在 LeetCode 算法题中经常如下定义:
public class ListNode {
public int data;
public ListNode next;
ListNode(int x) {
data = x;
// 只是为了规范
next = null;
}
}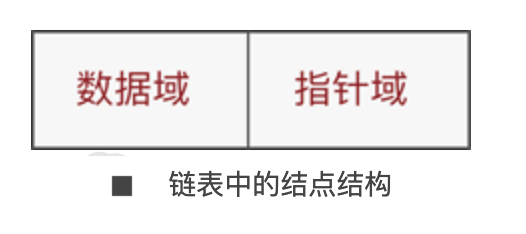
在链表中每个结点的基本结构就是如上图所示;
3. 链表的增删改查
3.1. 遍历
对于单链表来说,增删改查都是从头结点开始进行逐个访问,所以头结点很重要,不能丢失。
public static int getListNodeLength(ListNode head) {
int length = 0;
ListNode node = head;
// 尾结点的后继指针指向 NULL
while (node != null) {
length++;
node = node.next;
}
return length;
}3.2. 插入
单链表的插入,相对也比较简单,但是在实际编码中需要小心。
(1) 在链表头部插入
head 表示插入前的头结点,只需要将新结点 newNode 的 next 指向 head 即可。
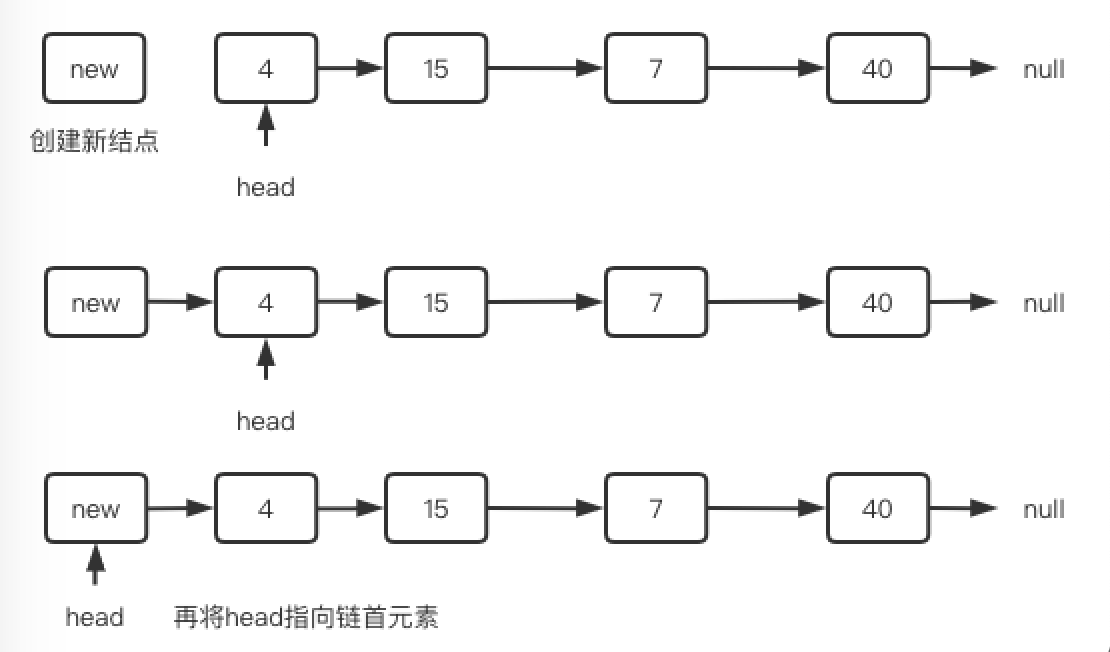
ListNode newNode = new ListNode(1);
newNode.next = head;
// 别忘将新的结点作为头结点
head = newNode;(2) 在链表中间插入
在中间插入新的结点,需要找到插入的位置,将前结点的 next 赋值给新结点的 next ,然后再将前结点的 next 指向新结点。注意顺序,顺序一旦出错,后继结点就会丢了。
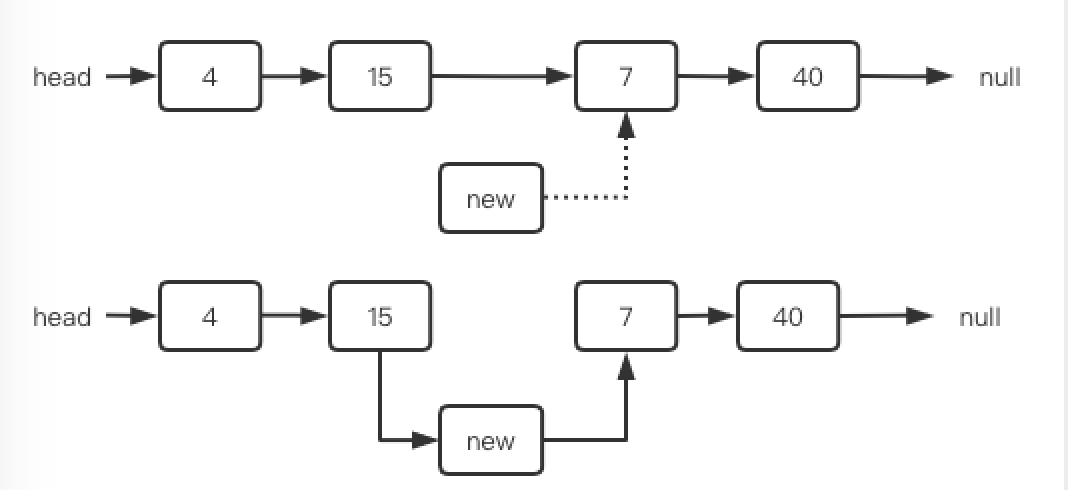
// 在目标值后插入
public ListNode insertNode(ListNode head, ListNode newNode, int target) {
ListNode node = head;
while (node.data != target) {
node = node.next;
}
newNode.next = node.next;
node.next = newNode;
}(3) 在链表尾部插入
此情况,只需要将尾结点的后继指针 next 指向新结点即可。
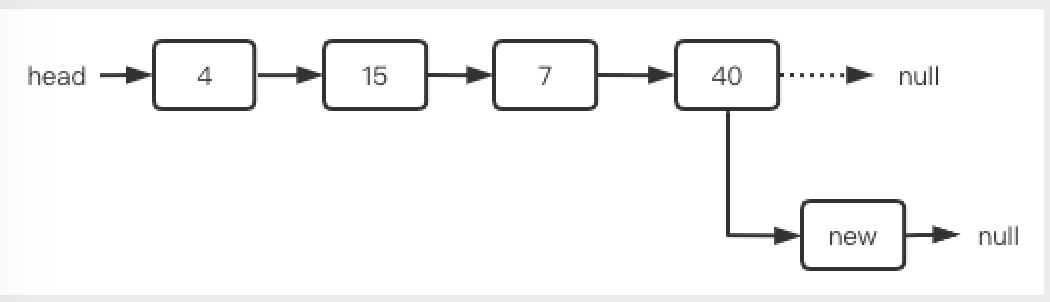
3.3. 删除
链表的删除较为简单,可分为删除头结点、删除中间结点和删除尾结点。
(1) 删除头结点
只需执行 head = head.next,原来的结点不可达,会被JVM回收掉。
(2) 删除中间结点
找到需要被删除结点的前驱结点,将前驱结点的后继指针 next 指向 node.next.next 即可。
(3) 删除尾结点
删除尾结点,需找到前驱结点,将前驱结点的后继指针 next 指向 NULL 即可。